The CPM is an extension of the PROV-DM provenance model (Figure 1). The provenance information is represented as a graph data structure with annotated nodes and edges. The nodes represent entities, activities, or agents, and the edges represent their mutual relations such as derivation, usage, generation, or attribution. The nodes and edges are referred to as provenance structures. Each provenance structure can be represented in provenance by one or more provenance statements. The CPM defines types of nodes which are a specialisation of the nodes defined in the PROV-DM. The specialisation is realised using prov:type attribute, which is a standardised way of PROV-DM to add further typing information to provenance structures. Every provenance structure can be identified with an identifier. Stipulated by the PROV-DM, the provenance structures identifier has the form of a qualified name.
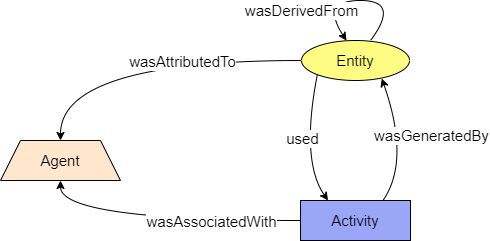
Figure 1: Conceptual structure of the W3C PROV-DM provenance model. Figure adapted from [Belhajjame2013] and cited from [Wittner2022].